
Short version:
I discovered a bug that would let any web page identify a logged in FB user by confirming their ID. Facebook fixed in 6-9 months and rewarded a $1000 bounty.
In last years coverage of the Facebook / Cambridge Analytica privacy concerns, Mark Zuckerberg was asked to testify before Congress, and one of the questions they asked was around whether Facebook could track users even on other websites. There was a lot of news coverage around this aspect of Facebook, and a lot of people were up in arms. As one aspect of their response, Facebook launched a Data Abuse Bounty, with the aim of protecting user data from abuse.
So, having recently found a bug in Google’s search engine, I set out to see whether I could track or identify Facebook users when they were on other sites. After a few false starts, I managed to find a bug which allows me to identify whether a visitor is logged in to a specific Facebook account, and can check hundreds of identities per second (in the range of 500 p/s).
I have created a proof of concept of the attack (now fixed), which checks both a small known list of IDs but also allows you to enter an ID and it will confirm whether you are logged in to that account or not.
Method
Facebook has a lot of backend endpoints which are used for various AJAX requests across the site. They are almost all are protected by access-control-allow-origin headers and magic prefixes on JSON responses that prevent JSON hijacking and other nasty attacks.
I searched across the site looking for any endpoints that didn’t have these protections and which did pass my user id in the URL, looking for any way I may be able to parse a response from Facebook to confirm whether the UID in the URL was correct.
I also looked for any images that include the user ID in the URL and behave differently when the UID matches the logged in user (so I could do something similar to this method, but for specific IDs); the closest I got was an image that did behave differently but the URL also included Facebook’s well known fb_dtsg parameter that is unique for users (and changes regularly) which prevented it being abused.
In addition I checked for any 301/302s in these URLs which might represent an opportunity to redirect to an image in a fashion would allow the same trick as above.
After carefully checking dozens of these endpoints I eventually found one that had a slight inconsistency in how it behaved which was a small gap but represented a weakness; it did have an access-control-allow-origin header, but it only included a magic prefix when the user ID (in the __user URL parameter) didn’t match, not when it did match. When the user ID provided in the URL did match the response was pure JSON.
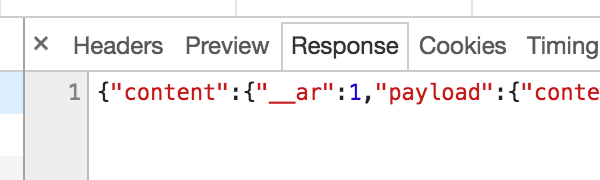
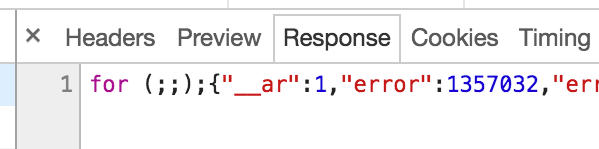
However, because of the pesky access-control-allow-origin header, I couldn’t call this via an XHR request as the browser would block it. At this point I thought it may be another dead end, but I eventually realised what I could do is use it as the src for a normal <script> block; this would of course fail but importantly it fails in a different way in both the cases (due also to the content-type header), and in such a fashion that this can be detected via onload and onerror event handlers.
Here is an example of the URL for the endpoint:
https://www.facebook.com/ajax/pagelet/generic.php/TimelineEntStoryActivityLogPagelet?dpr=2&ajaxpipe=1&ajaxpipe_token=AXjeDM6DZ_aiAeG-&no_script_path=1&data=%7B%22year%22%3A2017%2C%22month%22%3A9%2C%22log_filter%22%3A%22hidden%22%2C%22profile_id%22%3A1159016196%7D&__user=XXXXXXXXXXXX&__a=1&__dyn=7AgNe-4amaxx2u7aJGeFxqeCwKyWzEy4aheC267UqwWhE98nwgU6C4UKK9wPGi2uUG4XzEeUK3uczobrzoeonVUkz8nxm1typ8S2m4pU5LxqrUGcwBx-1-wODBwzg7Gu4pHxx0MxK1Iz8d8vy8yeyES3m6ogUKexeEgy9EhxO2qfyZ1zx69wyQF8uhm3Ch4yEiyocUiVk48a8ky89kdGFUS&__req=fetchstream_8&__be=1&__pc=PHASED%3ADEFAULT&__rev=3832430&__spin_r=3832430&__spin_b=trunk&__spin_t=1524222703&__adt=8&ajaxpipe_fetch_stream=1
I was then able to craft a simple Javascript script that would take a list of user IDs and generate many script tags with callbacks to determine success or failure. Because the endpoint is HTTP2 it also means you can have many of these requests in flight at once, which makes checking against large lists of IDs very quick. I did a small test here and was able to test 400-500 user IDs per second; if this was done in the background on a normal page that a user was on for a minute it would be possible to check thousands of IDs. There didn’t seem to be any sort of rate limiting on this endpoint.
Demo
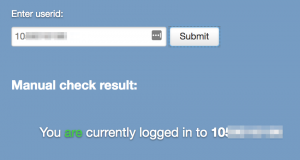
I have created a small demo which demonstrates the attack. It checks a small list of known user IDs automatically when you arrive on the page, and also allows you to enter an ID on the page and will confirm whether you are logged in to that account.
Impact
This is limited in that you need to be checking against a known list of users, rather than just being able to determine the user’s identity automatically. However, anyone affected by the Cambridge Analytica data situation whose data is already known, they would now be able to be identified and tracked across websites even without using any Facebook APIs.
In addition, the most sinister exploiters (e.g. a repressive regime) of such a bug would likely have a list of people they cared about identifying (which they could also narrow down based on your location and other factors). A final example might be anyone on a corporate IP address or network, where the list of users is probably fair easy to harvest and is fairly finite.
So the scope is fairly narrow, the impact on many may be small, but for some that impact could be high. This would certainly be a violation of privacy for any Facebook user who did get identified.
Disclosure Timeline
- 20th April 2018 – I filed the initial bug report.
- 20th April 2018 – Facebook replied letting me know this was being handed to the correct team to investigate.
- 1st May 2018 – I requested an update.
- 2nd May 2018 – FB replied – still investigating.
- 23rd May 2018 – I requested an update, noticing it was fixed in Chrome but not Safari.
- 23rd May 2018 – FB replied – they were investigating solutions.
- 20th June 2018 – FB awarded a $1000 bounty.
- 1st October 2018 – I requested permission to publish.
- 1st October 2018 – FB replied they were still working on the fix, and they’d update me.
- 19th February 2019 – I followed up and FB seemed happy for me to publish.
(It is unclear when the final fix rolled – it looks like 6-9 months after I reported it.)
2 responses to “Facebook exploit – Confirm website visitor identities”
well done
nice finding tom, very interesting read! thank