Short version:
Googlebot is based on Google Chrome version 41 (2015), and therefore it has no XSS Auditor, which later versions of Chrome use to protect the user from XSS attacks. Many sites are susceptible to XSS Attacks, where the URL can be manipulated to inject unsanitized Javascript code into the site.
Since Googlebot executes Javascript, this allows an attacker to craft XSS URLs that can manipulate the content of victim sites. This manipulation can include injecting links, which Googlebot will follow to crawl the destination site. This presumably manipulates PageRank, but I’ve not tested that for fear of impacting real sites rankings.
I reported this to Google in November 2018, but after 5 months they had made no headway on the issue (citing internal communication difficulties), and therefore I’m publishing details such that site owners and companies can defend their own sites from this sort of attack. Google have now told me they do not have immediate plans to remedy this.
Last year I published details of an attack against Google’s handling of XML Sitemaps, which allowed an attacker to ‘borrow’ PageRank from other sites and rank illegitimate sites for competitive terms in Google’s search results. Following that, I had been investigating other potential attack when my colleague at Distilled, Robin Lord, mentioned the concept of Javascript injection attacks which got me thinking.
XSS Attacks
There are various types of cross-site scripting (XSS) attack; we are interested in the situation where Javascript code inside the URL is included inside the content of the page without being sanitized. This can result in the Javascript code being executed in the user’s browser (even though the code isn’t intended to be part of the site). For example, imagine this snippet of PHP code which is designed to show the value of the page URL parameter:
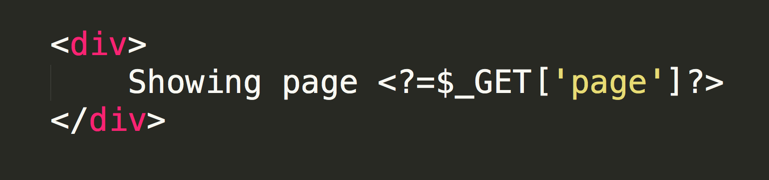
If someone was to craft a malicious URL where instead of a number in the page parameter they instead put a snippet of Javascript:
https://foo.com/stores/?page=<script>alert('hello')</script>
Then it may produce some HTML with inline Javascript, which the page authors had never intended to be there:

That malicious Javascript could do all sorts of evil things, such as steal data from the victim page, or trick the user into thinking the content they are looking at is authentic. The user may be visiting a trusted domain, and therefore trust the contents of the page, which are being manipulated by a hacker.
Chrome to the rescue
It is for that reason that Google Chrome has an XSS Auditor, which attempts to identify this type of attack and protect the user (by refusing to load the page):
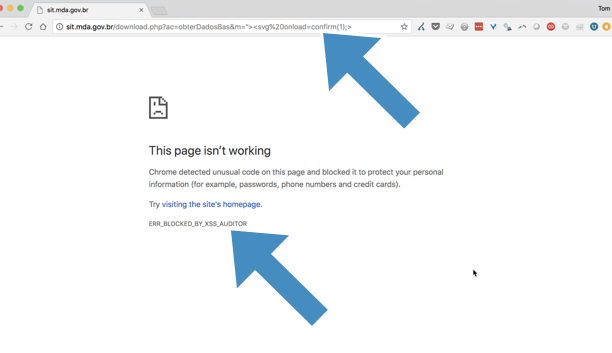
So far, so good.
Googlebot = Chrome 41
Googlebot is currently based on Chrome version 41, which we know from Google’s own documentation. We also know that for the last couple of years Google have been promoting the fact that Googlebot executes and indexes Javascript on the sites it crawls. Chrome 41 had no XSS Auditor (that I’m aware of, it certainly doesn’t block any XSS that I’ve tried), and therefore my theory was that Googlebot likely has no XSS Auditor.
So the first step was to check, whether Googlebot (or Google’s Website Rendering Service [WRS], to be more precise) would actually render a URL with an XSS attack. One of my early tests was on the startup bank, Revolut — a 3 year old fintech startup with $330M in funding having XSS vulnerabilities demonstrates the breadth of the XSS issue (they’ve now fixed this example).
I used Google’s Mobile Friendly Tool to render the page, which quickly confirms Google’s WRS executes the XSS Javascript, in this case I’m crudely injecting a link at the top of the page:
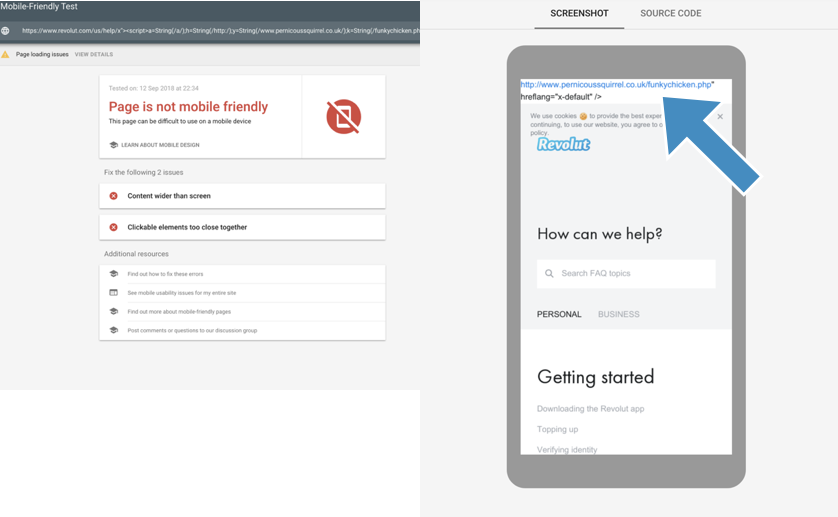
It is often (as in the case with Revolut) possible to entirely replace the content of the page to create your own page and content, hosted on the victim domain.
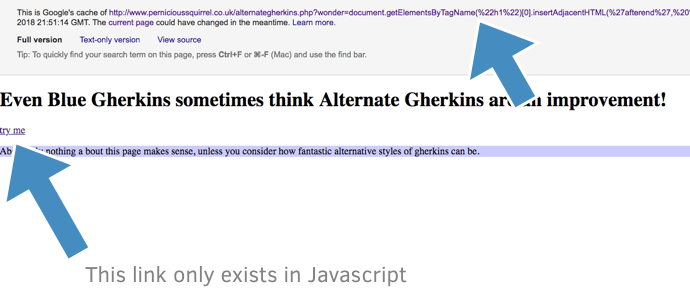
Content + links are cached
I submitted a test page to the Google index, and then examining the cache of these pages shows that the link being added to the page does appear in the Google index:
Canonicals
A second set of experiments demonstrated (again via the mobile friendly tool) that you can change the canonicals on pages:
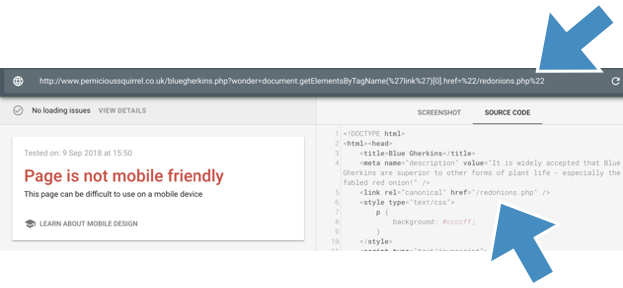
Which I also confirmed via Google’s URL Inspector Tool, which reports the injected canonical as the true canonical (h/t to Sam Nemzer for the suggestion):
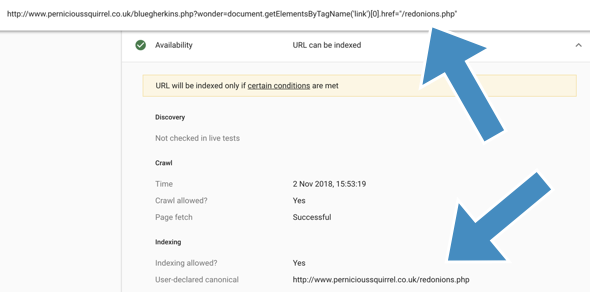
Links are crawled and considered
At this point, I had confirmed that Google’s WRS is susceptible to XSS attacks, and that Google were crawling the pages, executing the Javascript, indexing the content and considering the search directives within (i.e. the canonicals). The next important stage, is does Google find links on these pages and crawl them. Placing links on other sites is the backbone of the PageRank algorithm and a key factor for how sites rank in Google’s algorithm.
To test this, I crafted a page on Revolut which contained a link to a page on one of my test domains which I had just created moments before, and had previously not existed. I submitted the Revolut page to Google and later on Googlebot crawled the target page on my test domain. The page later appeared in the Google search results:
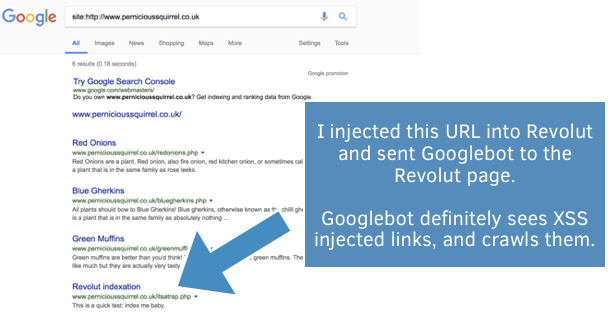
This demonstrated that Google was identifying and crawling injected links. Furthermore, Google confirms that Javascript links are treated identically to HTML links (thanks Joel Mesherghi):
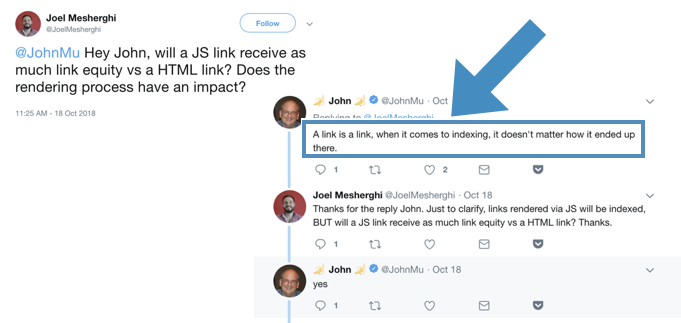
All of this demonstrates that there is potential to manipulate the Google search results. However, I was unsure how to test this without actually impacting legitimate search results, so I stopped where I was (I asked Google for permission to do this in a controlled fashion a few days back, but not had an answer just yet).
How could this be abused?
The obvious attack vector here is to inject links into other websites to manipulate the search results – a few links from prominent sites can make a very dramatic difference to search performance. The https://www.openbugbounty.org/ lists more than 125,000 un-patched XSS vulnerabilities. This included 260 .gov domains, 971 .edu domains, and 195 of the top 500 domains (as ranked by the Majestic Million top million sites.
A second attack vector is to create malicious pages (maybe redirecting people to a malicious checkout, or directing visitors to a competing product) which would be crawled and indexed by Google. This content could even drive featured snippets and appear directly in the search results. Firefox doesn’t yet have adequate XSS protection, so this pages would load for Google users searching with Firefox.
Defence
The most obvious way to defend against this is to take security seriously and try to ensure you don’t have XSS vulnerabilities on your site. However, given then numbers from OpenBugBounty above, it is clear that that is more difficult that it sounds – which is the exact reason that Google added the XSS Auditor to Chrome!
One quick thing you can do is check your server logs and search for URLs that have terms such as ‘script’ in them, indicating a possible XSS attempt.
Wrap up
This exploit is a combination of existing issues, but combine to form an zero-day exploit that has potential to be very harmful for Google users. I reported the issue to Google back on November 2018, but they have not confirmed the issue from their side or made any headway addressing it. They cited “difficulties in communication with the team investigating”, which felt a lot like what happened during the report of XML Sitemaps exploit.
My impression is that if a security issue affects a not commonly affected part of Google, then the internal lines of communication are not well oiled. It was March when I got the first details, when Google let me know “that our existing protection mechanisms should be able to prevent this type of abuse but the team is still running checks to validate this” – which didn’t agree with the evidence. I re-ran some of my tests and didn’t see a difference. The security team themselves were very responsive, as usual, but seemingly had no way to move things forward unfortunately.
It was 140 days after the report when I let Google know I’d be publicly disclosing the vulnerability, given the lack of movement and the fact that this could already be impacting both Google search users, as well as website owners and advertisers. To their credit, Google didn’t attempt to dissuade me and asked me to simply to use my best judgement in what I publish.
If you have any questions, comments or information you can find me on Twitter at @TomAnthonySEO, or if you are interested in consulting for technical/specialised SEO, you can contact me via Distilled.
Disclosure Timeline
- 3rd November 2018 – I filed the initial bug report.
- Over the next few weeks/months we went back and forth a bit.
- 11th February 2019 – Google responded letting me know they were “surfacing some difficulties in communication with the team investigating”
- 17th April 2018 – Google confirmed they have no immediate plans to fix this. I believe this is probably because they are preparing to release a new build of Googlebot shortly (I wonder if this was why the back and forth was slow – they were hoping to release the update?)
can this trick works now?i want to check? what will be the code if i want to a specific page of mine to other domain, let me know
In the timeline is April 18 2018 supposed to be 2019?
Thanks
Thanks for this, Tom… VERY concerning, particularly with Google’s response being “… do not have immediate plans to remedy this.”
You’ve just got a new follower! 😉
Nice finding, Tom.
By the way, some Russian guy has translated this article, but I rather prefer the original.
I have a feeling that last update in disclosure timeline has the wrong year in it.
Google just announced at I/O that they would use the latest version of Chromium from now on to crawl.
Looks like google pushed that Googlebot build update today for Chrome 74. Wonder if that means this is fixed?